Writing Reliable Software#
This week we will start to look closer at how to write reliable and readable software. How should we develop code that is trustworthy? In this lecture we look closer at assertions, exceptions and testing, and in the next lecture we look at code style and documenting code.
What constitutes reliable software?#
To say that software is reliable means that we should be able to trust it. Ideally speaking, this means the program should produce answers that are correct. However, how can we trust that the answers are correct? And what should happen if we meet edge cases were we can no longer be sure that the output will be correct? To explain what we mean when we say reliable, let us list some important points:
Software should not return incorrect results
Software should fail rather than return incorrect results
Software should fail in controlled ways
Software should be tested solidly
Ideally we want our code to produce correct results, but we would much rather that our program fail than it return incorrect results. And when it fails, it should fail in controlled ways, i.e., it should ideally give some nice error message we can use to understand what went wrong. A program shouldn’t corrupt any data files or similar if it has to halt half-way through running, and so on. Lastly, the only way to trust our software is to test it. It doesn’t matter how competent a programmer, there will always be bugs, and testing can help us track these down.
Let us look closer at achieving these elements of reliable software in Python. First we cover how to write programs that fail on purpose in a controlled manner, and then we turn to testing.
Assertions#
The first thing we shall talk about are assertions. Most programming language support writing assertions in a simple manner. Assertions are meant to be very simple “emergency stops” in our code and can be a nice and simple way to “idiot proofing” your code. The idiot in this case can be other users of your code, but also your future self.
In Python an assertion is written using the assertion keyword, followed by a condition that is evaluated to either true or false, much like an if-test:
assert <condition>
If the condition is true, the assertion does nothing and the code continues. If it is false, the program crashes with an AssertionError. In this sense, an assertion is a check that checks if some requirement is fulfilled, if it isn’t, the execution of the program is stopped.
In addition to the condition itself, we can put in a string that is given to the user in case of failure:
assert <condition>, "fail message"
It is useful to add a simple message, as it makes it easier to understand what went wrong and fix it.
Let us look at a specific example
class Sphere:
def __init__(self, radius):
assert radius >= 0, "Radius cannot be negative."
self.radius = radius
Here, we are defining there Sphere-class that we discussed in last week’s lecture. The constructor takes the radius of the Sphere as an argument, and the class can have various functionality added. Now, we know that a negative radius doesn’t make any sense, but Python doesn’t know this. So it is completely possible to add a negative radius. We therefore add an assert to check the input.
If we now try to define a sphere as normal, it works fine, but if we try to do something like:
Sphere(-4)
we get the following error
AssertionError: Radius cannot be negative.
Adding the assertion takes us about 10 seconds. But it can potentially save us, or others, a lot of frustration later, as it might catch a bug where someone misunderstands how our class works, or perhaps have a different bug where they send the wrong variable in as an argument.
Assertions can also be put into programs to check for “can’t happen” scenarios. To understand where it makes sense to put assertions, think of how you yourself look for a bug in a program that is misbehaving. You probably put in various print statements to check inputs, outputs, types, and so forth. When you do this, an alternative would be to put in asserts checking what you expect to be the case at logical locations. If these assertions fail, you have probably found your bug. The benefit of putting in asserts is that your program will now also catch bugs that might arise later.
Assertions are closely linked to something called programming invariants in computer science. The invariants of a program, solution or algorithm are statements the programmer can rely on being true. Invariants are important when doing more formal software development, as it is a concrete way to making sure correct behavior can be checked or enforced, which can be important for future use and reliableness.
Disabling Assertions#
Assertions are nice because they are fast to write, but also efficient to run. Having assertions in your code most likely won’t cause any significant slow-down. However, in Python we can also run in and “optimized” mode were assertions are ignored. Say an assertion for example occurs inside a function that is called repeatedly in a large loop or something, then it might be nice to run without checking the assertions. This can be done by running Python with the -O flag:
python -O run_simulation.py
This flag only does two things:
completely ignores any assertion
sets the builtin variable
__debug__to False (it is True by default)
Exceptions#
Assertions were used to abort the program given that some condition was not met. However, there is a different way to halt the execution of a program in a controlled manner, raising exceptions.
We raise an exception by using the raise keyword as follows
raise <exception>
where we fill the proper exception type. All the normal “errors” you get in Python (TypeError, NameError, etc) are exceptions. So in our Sphere example as before, we could change our assertion to raising an error:
class Sphere:
def __init__(self, radius):
if radius < 0:
raise ValueError("Radius cannot be negative")
self.radius = radius
Note that we put the error message as a string into the constructor of the exception (because the exceptions are classes in Python). This time, if we try to define Sphere(-4) the program crashes, but with the error message
ValueError: Radius cannot be negative.
One apparent benefit of raising an error over the assertion is that it provides more information. The ValueError tells us it’s something with the value that is going wrong. This type is also very important when we catch exceptions.
Catching Exceptions#
When a exception is raised, for example during a function call, it will crash the program, unless that exception is caught. In Python, we catch exceptions by putting them inside a try-block. Let us for example we have a long list of values, and we want to create a corresponding list of Spheres, with radii given by those values. However, the values are sometimes negative, in which case we want the radii to be set to 0. We could then do the following
class Sphere(Sphere):
def __repr__(self):
return self.__class__.__name__ + f"({self.radius})"
data = [4.5, -1.1, 3.4, 2.7, -0.2, 6.3]
spheres = []
for d in data:
try:
spheres.append(Sphere(d))
except ValueError:
spheres.append(Sphere(0))
print(spheres)
[Sphere(4.5), Sphere(0), Sphere(3.4), Sphere(2.7), Sphere(0), Sphere(6.3)]
The Try/Except structure has a fairly intuitive names in Python. First we try something, if something specific goes wrong, we do something else. We could for example try opening a file, but if there is no file, we could instead make one, or choose to use some default data, or ask the user for a new file. In most languages it is also called “try”, but instead of “except” we call it “catch”. This is because raising an error is also referred to throwing an error, and we can then throw an error somewhere in the code, for example inside a function, and then catch it and handle it somewhere else.
Note that we specifically catch a ValueError, because we know this is what can go wrong. It is possible to just write except:, and this catches any exception. However, this is not recommended, because this would also catch a simple syntax error inside the Sphere class for example—which should crash the program. Because we catch a ValueError specifically, we let all other errors still go through to the user as desired.
You can also catch errors of different types and handle them similarly as follows:
try:
...
except (ValueError, TypeError):
...
or you can have several, different except blocks:
try:
...
except ValueError:
...
except TypeError:
...
You can also get the error message of the error if you write
except ValueError as e:
...
in which case e will be a string with the error message.
Error types in Python#
In Python, there is a general superclass for all errors called simply Exception. All other errors inherit from this class. The following diagram shows all the built in errors
+-- Exception
+-- StandardError
| +-- ArithmeticError
| | +-- FloatingPointError
| | +-- OverflowError
| | +-- ZeroDivisionError
| +-- AssertionError
| +-- AttributeError
| +-- EnvironmentError
| | +-- IOError
| +-- EOFError
| +-- ImportError
| +-- LookupError
| | +-- IndexError
| | +-- KeyError
| +-- NameError
| +-- RuntimeError
| | +-- NotImplementedError
| +-- SyntaxError
| | +-- IndentationError
| | +-- TabError
| +-- SystemError
| +-- TypeError
| +-- ValueError
Any of these can be raised and caught in your code.
Defining Custom Exceptions#
There are many built in exceptions and errors that can be used to make your errors more specific. However, it is also trivial to define custom exceptions in your code. Simply subclass an existing exception class, or Exception itself.
Why would you want to define your own custom exceptions? For larger projects these can be nice, as they can make it even clearer what is going wrong, or they can make sure that you are catching exactly the bug you are expecting. Say for example our earlier Sphere example, where the radius shouldn’t be negative. We could raise a ValueError, but we could also create a custom exception that can be even more specific.
class NegativeRadiusError(Exception):
pass
class Sphere:
def __init__(self, radius):
if radius < 0:
raise NegativeRadiusError("Radius must be non-negative")
self.radius = radius
def shrink(self, shrinkage):
if self.radius - shrinkage < 0:
raise NegativeRadiusError("Radius would become negative.")
self.radius -= shrinkage
try:
s = Sphere(2)
s.shrink(3)
except NegativeRadiusError as e:
print(e)
Radius would become negative.
Here we subclass the Exception class with a new custom exception called NegativeRadiusError. We just write pass because we are not overwriting any functionality from the exception class, we are just defining a new class with a custom name. Now we are free to raise and catch this error in the rest of our code.
Assertions vs other Exceptions#
We have now covered how we can use both assert statements, and raising exceptions to get a program to fail controllably. But for which cases should you use asserts and when should you use exceptions? The main benefit of asserts are that they are very fast to implement, and that they can be turned of to run in “optimized” mode. The main benefit of raising exceptions is that we can be more specific with the exception type, which can then be easier to catch and handle in other parts of the program.
Because of their benefits, asserts should be used to test for conditions that should never happen. We use them mostly as an aid when developing the code. For any error that we expect to possibly happen during normal use of the software should instead raise exceptions, which will be much better for the end user due to the better information and handling possibilities.
Testing#
So far we have talked about how to get the program to fail in a controlled manner. Now we turn to how to test code. When writing larger pieces of software, we will make mistakes, 100 % guaranteed. Tests let us catch these errors before the software is used for something important.
Testing code means checking if it is behaving as expected, and that it meets our requirements. Software testing is a large and broad field, and its possible to work as a dedicated software tester. In IN1910 we won’t go too in depth in testing, but show you some nice tools to test your own code. Testing is an essential part of quality assurance, and for software to be considered high quality it has to include testing. Others won’t trust your code if it isn’t tested, and neither should you.
One of the simplest forms of testing, and the one we will focus most on in IN1910, is called unit testing.
Unit Testing#
A unit test is a test of a small component of a program, a single “unit”. If we are talking about object-oriented programming, a unit test would for example check that a single method of a class does what it is expected to do. When unit testing a piece of code, we are checking that piece of code is working in isolation. The unit test offers no insurance the the code as a whole works, but at least we can feel more confident in that piece of the code. While this might sound like unit tests are too simple, it also makes them straight-forward to think up and implement. When starting a new project, you can write a piece of code, then make the unit tests for that piece of code right there and then. Verifying that the the whole code works on the other hand, won’t be possible until you’ve written the whole code.
Another important point about unit tests is that they should be automated, meaning that it should be a a test case that can run by itself, and also check whether it passes or fails by itself. This way, we write the unit test once, and then run it every time we change the code to make sure nothing is broken. The goal of automated testing is of course efficiency, but also that we don’t get sloppy over time. To automate the process of making and running tests, we want to use a package meant for unit testing.
The pytest package#
As with everything else in software, many packages exist for unit testing in Python. In fact, Python has its own built in package called unittest which we could use. Other popular choices are pytest, doctest and nose. These all have slightly different syntax, workflow, and use cases, but in most regards they are quite similar. In IN1910, we only write fairly simple tests, and all of these frameworks would work well. We opt to go for pytest because it by far the most used testing library in python, it is easy to use but also has a lot of powerful extensions if you want to use more advanced testing features.
Note that while we use pytest to write our unit tests, the concept of unit testing doesn’t rely on any specific framework, the important takeaways are the ideas.
We use the rest of this lecture to show example of how to write unit tests in pytest. If you want a more thorough introduction to pytest, the following tutorials might be helpful
Before you continue, you should make sure that you have pytest installed. pytest is not part of the standard library, but can easily be installed with e.g pip
!pip3 install pytest
pytest basics#
As we said earlier, the main goal of unit tests is to automate things, pytest therefore finds our tests automatically. It does this by assuming everything (files, functions, classes) with a name beginning with test or Test is a test. When we ask pytest to run tests it looks for these tests and runs all of them, and giving us a report back about which ones succeeded and which ones failed. Any test that finishes executing without throwing an exception succeeds, any test that throws an exception fails.
It is very useful to put all your tests into one or several files with names starting with test_. By keeping tests separate from your source code, you keep everything nice and tidy.
Unit testing examples with Vector3D#
As a running example of unit testing, we will use the Vector3D class we made during the previous lecture. In this case we have our source code in the file vector.py. And we would put all our tests in a separate file called test_vector.py. In these lecture notes we simply import the Vector3D class and test it directly to show examples. But we also put the test_vector.py file there so you can try running pytest yourself.
Let’s start writing some unit tests for Vector3D. To do this we first have to think of examples of how the code should behave. Let us for example define to vectors
\(u = (1,2,0)\)
\(v = (1, -1, 3)\)
And then we can compute by hand:
\(u+v = (2, 1, 3)\)
\(u-v = (0, 3, -3)\)
\(u\cdot v = -1\)
\(||u||^2 = 5\)
\(||v||^2 = 11\)
So we know what these simple computations should be. What we do now is implement a unit test to check if this is actually the case for our code.
First, we want to check that u + v gives us the expected values. To check this we use assertions. We can write this test out as follows:
from vector import Vector3D
def test_add():
u = Vector3D(1, 2, 0)
v = Vector3D(1, -1, 3)
w = u + v
assert w.x == 2
assert w.y == 1
assert w.z == 3
In this test we create two vectors and add them together like we would when using the class normally. Then we check the result using assert w.z == 3. If these pass, meaning the results are as expected, the test passes (we don’t need to return true or anything like that). If they fail, the test fails.
Because this function’s name starts with test_, it will automatically be found an run by pytest. You can run pytest from the command line by writing
pytest
or
py.test
Another way to run pytest is to execute it as a module
python3 -m pytest
This is very handy if you have different versions of python installed and want to be certain that you run pytest with the version that you want. In which case it looks for all tests in the current folder and any sub-folders. Or you could run it on a specific folder by writing
pytest <folder>
If we run pytest now, we get the following output
collected 1 item
test_vector.py . [100%]
============================================== 1 passed in 0.14 seconds ===============================================
It ran 1 test, because that is all we have written so far. It says the test passed, which means there were no exceptions or assertion errors. This means our add function works as expected, at least for this input!
Let us produce an error on purpose to see how that looks. We go and change the Vector3D.__add__ method so that we do something wrong on purpose, say for example:
x = self.x + other.x
y = self.x + other.x
z = self.z + other.z
(Copying and pasting code that needs small adjustments is an extremely common place for errors). We would get the following result from pytest:
collected 1 item
test_vector.py F [100%]
====================================================== FAILURES =======================================================
______________________________________________________ test_add _______________________________________________________
def test_add():
u = Vector3D(1, 2, 0)
v = Vector3D(1, -1, 3)
w = u + v
assert w.x == 2
> assert w.y == 1
E assert 2 == 1
E + where 2 = Vector3D(2, 2, 3).y
test_vector.py:9: AssertionError
============================================== 1 failed in 0.19 seconds ===============================================
The test fails because w.y would become 2, because of the bug, but we assert it to be 1. Note that the error message points to which line the error occurs(>assert w.y == 1), and explains what the wrongfully assertion is(2 == 1).
The statement assert effectively asserts that two variables are equal, i.e., that a == b is true. In this case, we checked each component separately. However, we could also try assert w == Vector3D(2, 1, 3), but this would fail. This is because we are comparing custom objects, and when comparing custom objects, Python defaults to comparing their location in memory. Because we are comparing two different objects, this would therefore fail by default.
To make vectors comparable by their values, we need to add a __eq__ special method to our Vector3D method, when we check for equality by doing u == v, this is equivalent to calling u.__eq__(v), so our method should return a True or a False.
class Vector3D(Vector3D):
def __eq__(self, other):
same_x = abs(self.x - other.x) < 1e-12
same_y = abs(self.y, other.y) < 1e-12
same_z = abs(self.z, other.z) < 1e-12
return same_x and same_y and same_z
In stead of asserting that the numbers are equal, we instead check that the two numbers are close, by checking that the absolute value of their difference is less that some tolerance (here \(10^{-12}\)).
When testing for equality of floating point numbers, you should always check that numbers are close in stead of strict equality. The reason is that floating point operations can lead to round off errors which can be seen in the following example
a = 1.2
b = 1.0
print(a - b)
assert a - b == 0.2
0.19999999999999996
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
Cell In[6], line 4
2 b = 1.0
3 print(a - b)
----> 4 assert a - b == 0.2
AssertionError:
The output from this would yield the following
0.19999999999999996
AssertionError
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
<ipython-input-10-8ca4158e488d> in <module>
2 b = 1.0
3 print(a - b)
----> 4 assert a - b == 0.2
AssertionError:
With the equality method implemented, let’s write a unit test to check if it works
def test_eq():
u = Vector3D(1, 2, 0)
assert u == Vector3D(1, 2, 0)
assert u == Vector3D(1.00000001, 2, 0)
assert u != Vector3D(1, 2, 1)
assert u != Vector3D(1.001, 2, 0)
First note that we need to define a new vector to test with, because each unit test we write is a separate function, they don’t see each other. Sometimes stated as: “Each unit test is an island.”. We write four assertions:
two vectors of the same components should be equal
two vectors with a small round-off error should also be equal
two vectors with a different component should not be equal
two vectors with a small, but noticeable difference, should not be equal
Running the tests with pytest show that things are working as expected. With the __eq__ implemented and tested we could now write out the add test as follows
def test_add():
u = Vector3D(1, 2, 0)
v = Vector3D(1, -1, 3)
assert (u + v) == Vector3D(2, 1, 3)
Let us move on and make a few more tests for the following cases:
\(u+v = (2, 1, 3)\)
\(u-v = (0, 3, -3)\)
\(u\cdot v = -1\)
\(u\times v = (6, -3, -3)\)
\((u\times v)\cdot u = 0\) and \((u\times v)\cdot v = 0\)
\(||u||^2 = 5\)
\(||v||^2 = 11\)
def test_sub():
"""Test subtraction"""
u = Vector3D(1, 2, 0)
v = Vector3D(1, -1, 3)
assert (u - v) == Vector3D(0, 3, -3)
def test_dot():
"""Test dot product"""
u = Vector3D(1, 2, 0)
v = Vector3D(1, -1, 3)
assert u.dot(v) == -1
assert u * v == -1
def test_cross():
"""Test cross product"""
u = Vector3D(1, 2, 0)
v = Vector3D(1, -1, 3)
assert u.cross(v) == Vector3D(6, -3, -3)
assert u @ v == Vector3D(6, -3, -3)
def test_perp():
"""Test perpendicularity"""
u = Vector3D(1, 2, 0)
v = Vector3D(1, -1, 3)
assert not u.perpendicular(v)
assert (u @ v).perpendicular(u)
assert (u @ v).perpendicular(v)
def test_length():
"""Test length"""
u = Vector3D(1, 2, 0)
v = Vector3D(1, -1, 3)
assert (u.length**2 - 5) < 1e-12
assert (v.length**2 - 11) < 1e-12
We can now run our tests are before, and we will get the following output
collected 7 items
test_vector.py ....... [100%]
============================================== 7 passed in 0.05 seconds ===============================================
Every test passed! Not very surprising as we had already tested our code somewhat with simple examples during the previous lecture. But this is a lot more formal and rigorous, and shows anyone who missed that lecture that it seems to be working.
To get more feedback on what tests are run, we can add the -v flag:
pytest -v
to get the output:
collected 7 items
test_vector.py::test_add PASSED [ 14%]
test_vector.py::test_eq PASSED [ 28%]
test_vector.py::test_sub PASSED [ 42%]
test_vector.py::test_dot PASSED [ 57%]
test_vector.py::test_cross PASSED [ 71%]
test_vector.py::test_perp PASSED [ 85%]
test_vector.py::test_length PASSED [100%]
============================================== 7 passed in 0.11 seconds ===============================================
Asserting exception raising#
One last thing we often want to check for, is that an exception is actually raised given the right conditions. This can easily be implemented using something called a context manager. When testing for an exception we want to allow a specific exception to be raised, but we would also like to fail the test if that specific exception was not raised.
To do this we create a context block using a with statement as be calling pytest.raises, pytest will listen for for the exception that we provided within that context block, and fail the test if we exit the block without the specific exception raised.
import pytest
def test_no_scalar_addition():
with pytest.raises(TypeError):
Vector3D(1, 1, 0) + 3
In this case, we check that a vector \(u\) plus a scalar \(3\) is undefined as a TypeError. Note that here we also need to import pytest because we are using a function from the pytest library.
Let us show a different one
def test_no_unit_vector():
with pytest.raises(RuntimeError):
Vector3D(0, 0, 0).unit()
Which verifies that we cannot find a unit-vector for a vector with zero length. When we now run pytest we get the following output (changed somewhat for readability in the notebook)
collected 9 items
test_vector.py ........F [100%]
====================================================== FAILURES =======================================================
_________________________________________________ test_no_unit_vector _________________________________________________
def test_no_unit_vector():
with pytest.raises(RuntimeError):
> Vector3D(0, 0, 0).unit()
E Failed: DID NOT RAISE <class 'RuntimeError'>
test_vector.py:79: Failed
This means the last test failed, but the other 8 passed. The last test fails because we never added functionality that raises an exception for the zero-length vector case. Let us add this now.
class Vector3D(Vector3D):
def unit(self):
if self.length == 0:
raise RuntimeError("Vector of zero length has no unit vector.")
new_vector = Vector3D(self.x, self.y, self.z)
new_vector.length = 1
return new_vector
And after adding this, our test passes!
Parametrized tests#
Imagine that you want to test your functions against different input. Let us take the test_length function we wrote above
def test_length():
"""Test length"""
u = Vector3D(1, 2, 0)
v = Vector3D(1, -1, 3)
assert (u.length**2 - 5) < 1e-12
assert (v.length**2 - 11) < 1e-12
In this test we test two things. First we test that the squared length of u equals 5 and then we test that the squared length of v equals 11. Futhermore, if the first test fails, then assert statement will raise an AssertionError and the test will fail. As a consequence, the second test will never run. Sometimes, this is OK, but in many situations you want to get as much information as possible from your tests. If for example both these cases are failing it might indicate that there is something wrong with the way we have implemented the .length method while if only the first test case fails it might be only a problem in the test.
Another scenario that you could imagine is if you wanted to test your code against a large number of examples (say 10 or even 100 different examples). In that case you have to copy and paste the code above a lot and this would go again the DRY (Don’t Repeat Yourselves) principle.
Lets have a look at some ways we can deal with this.
First of all, note that if we let arg = (1, 2, 0), we can create a new vector as follows
arg = (1, 2, 0)
u = Vector3D(arg[0], arg[1], arg[2])
In fact, this is a good opportunity to show the unpacking operator in python. In this case we can actually do the following
arg = (1, 2, 0)
u = Vector3D(*arg)
The * is called an unpacking operator so that *arg unpacks the list so that Vector3D(*arg) is identical to Vector3D(arg[0], arg[1], arg[2]) when arg is a list of three elements.
Anyway, with this in mind we can now rewrite our tests as a for loop
def test_length_with_multiple_inputs():
args = [(1, 2, 0), (1, -1, 3)]
expected_values = [5, 11]
for (arg, expected) in zip(args, expected_values):
u = Vector3D(arg[0], arg[1], arg[2])
assert (u.length**2 - expected) < 1e-12
This will fix the copy-passing issue since any new examples could now just be added to the list. However, if the first test fails it will still not run the remaining tests.
Luckily, pytest provides a way to run all these cases in a simple way without the execution stopping if one of the tests are failing. This is called parameterized testing. The following code implements the same tests but will not stop the execution if one of the tests fail
import pytest
@pytest.mark.parametrize("arg, expected", [[(1, 2, 0), 5], [(1, -1, 3), 11]])
def test_length_parameterized(arg, expected):
u = Vector3D(arg[0], arg[1], arg[2])
assert (u.length**2 - expected) < 1e-12
The perhaps strange looking code starting with an @ is called a decorator which we will learn more about later in course. For now you can think of it as a function which modifies the function below it. In this case it will create a new function for each parameter set that is provided.
When running pytest against this function it will output the following
$ python -m pytest -k test_length_parameterized -v
======================== test session starts ========================
platform darwin -- Python 3.9.2, pytest-6.2.4, py-1.10.0, pluggy-0.13.1 -- /Users/henriknf/miniconda3/envs/IN1910-book/bin/python
cachedir: .pytest_cache
rootdir: /Users/henriknf/local/src/IN1910/IN1910_dev/book/docs/lectures/python_development
plugins: anyio-2.2.0, cov-2.12.0
collected 12 items / 10 deselected / 2 selected
test_vector.py::test_length_parameterized[arg0-5] PASSED [ 50%]
test_vector.py::test_length_parameterized[arg1-11] PASSED [100%]
================= 2 passed, 10 deselected in 0.11s ==================
and we see now that it runs two tests.
The first argument to @pytest.mark.parametrize is a string with the name of the arguments that should be passed to the function. The second argument is the actual input that should be passed to the function in each iteration. Here is another example
import pytest
def square(x):
return x**2
@pytest.mark.parametrize("x, x2", [(0, 0), (1, 1), (2, 4), (3, 9)])
def test_square(x, x2):
assert square(x) == x2
which will output the following
$ python -m pytest -k test_square -v
======================== test session starts ========================
platform darwin -- Python 3.9.2, pytest-6.2.4, py-1.10.0, pluggy-0.13.1 -- /Users/henriknf/miniconda3/envs/IN1910-book/bin/python
cachedir: .pytest_cache
rootdir: /Users/henriknf/local/src/IN1910/IN1910_dev/book/docs/lectures/python_development
plugins: anyio-2.2.0, cov-2.12.0
collected 16 items / 12 deselected / 4 selected
test_vector.py::test_square[0-0] PASSED [ 25%]
test_vector.py::test_square[1-1] PASSED [ 50%]
test_vector.py::test_square[2-4] PASSED [ 75%]
test_vector.py::test_square[3-9] PASSED [100%]
================= 4 passed, 12 deselected in 0.13s ==================
You can read more about parameterized test at the pytest documentation page.
We have now covered what we want to cover on making and running unit tests in pytest. For the remainder of this lecture we will cover some more terminology and theory on testing.
Running only a subset of your tests with pytest#
A very handy tip is to know how to run only a subset of your tests. If you have many tests then running all tests when you develop a new tests can be inconvenient. You can do this using the -k option. For example
python -m pytest -k test_square
will run all tests functions whose name starts with test_square. This means that if you have a test called test_square_root then that will also be run. It is there good practice to name your functions in a way that you could run only that test.
For large projects you might have multiple files with tests. A common pattern is to create a test folder containing all tests, see for example the wily project which has a very nice structure.
In this case you want add either the path to the file you want to run, e.g
python -m pytest tests/test_vector.py
Get print output when running tests#
Sometimes you might experience that your tests is not behaving as expected. The natural thing to do in this case is to add a few print statements to get some more information. However, it you do this and then try to run pytest you will not see anything being printed. This is because pytest turns off all printing by default. You can turn this on again if you pass in the -s option, e.g
python -m pytest -s
and this can of course also be combined with other options for example if we add a print statement to the test_square function
@pytest.mark.parametrize("x, x2", [(0, 0), (1, 1), (2, 4), (3, 9)])
def test_square_root(x, x2):
print("\nInput = ", x, ", output = ", x2)
assert square(x) == x2
we get the following
$ python -m pytest -k test_square -sv
======================== test session starts ========================
platform darwin -- Python 3.9.2, pytest-6.2.4, py-1.10.0, pluggy-0.13.1 -- /Users/henriknf/miniconda3/envs/IN1910-book/bin/python
cachedir: .pytest_cache
rootdir: /Users/henriknf/local/src/IN1910/IN1910_dev/book/docs/lectures/python_development
plugins: anyio-2.2.0, cov-2.12.0
collected 16 items / 12 deselected / 4 selected
test_vector.py::test_square_root[0-0]
Input = 0 , output = 0
PASSED
test_vector.py::test_square_root[1-1]
Input = 1 , output = 1
PASSED
test_vector.py::test_square_root[2-4]
Input = 2 , output = 4
PASSED
test_vector.py::test_square_root[3-9]
Input = 3 , output = 9
PASSED
================= 4 passed, 12 deselected in 0.11s ==================
Debugging tests#
When print statements doesn’t help you you can try using the built in debugger in python. If you are using python3.7 or above (which you should), then you can drop into a debugger anywhere in your code by calling the breakpoint() function.
For example let us try to add a breakpoint in the test_square function
@pytest.mark.parametrize("x, x2", [(0, 0), (1, 1), (2, 4), (3, 9)])
def test_square_root(x, x2):
breakpoint()
assert square(x) == x2
Running pytest now will drop you into a debug shell
$ python -m pytest -k test_square
======================== test session starts ========================
platform darwin -- Python 3.9.2, pytest-6.2.4, py-1.10.0, pluggy-0.13.1
rootdir: /Users/henriknf/local/src/IN1910/IN1910_dev/book/docs/lectures/python_development
plugins: anyio-2.2.0, cov-2.12.0
collected 16 items / 12 deselected / 4 selected
test_vector.py
>>>>>>>>>>>>>> PDB set_trace (IO-capturing turned off) >>>>>>>>>>>>>>
> /Users/henriknf/local/src/IN1910_H21/book/docs/lectures/python_development/test_vector.py(94)test_square_root()
-> assert square(x) == x2
(Pdb)
and now you have access to all the variables like you would have in a normal python shell. You can also type help to see a list of specific commands you can use with the debugger. The most important command are probably q (quit) and c (continue) and interact (which gives you an interactive python shell). You can read more about the python debugger in the official documentation.
A better debugger
If you want a better debugger than the built in one (with coloring and tab completion), I recommend a debugger called pdb++. You can install it with pip install pdbpp. Once this is installed it will use it by default.
Integration testing#
We have mostly talked about testing in the terms of unit testing, but this is obviously not the only kind of testing out there. On the other end of the spectrum we find integration testing, which is where we test a larger codebase to find out how the different components of the code base work together and integrate into a complete program or software package (The term isn’t directly connected to calculus). For scientific applications especially, this is quite important, because for larger mathematical modeling, comparing your output to analytical solutions or similar means we need to actually write an example use-case, which would be an example of an integration test.
An analogy could be to think of how a car is made. First, individual components of the car is made in different factories spread across several countries or even continents. Some make the wheels, some the axels, some the engine, etc. Each individual factory obviously need to test the components they are producing and shipping out. These “component tests” would be the unit tests. Finally, we have the factory that takes all the different components and builds the cars (the components are “integrated” into a car). When the car is finished, it too should be tested before being sold, which would be the integration tests.
As seen in the analogy, unit testing code and integration testing aren’t competitors, and good software needs both. However, the two are done in different parts of the development. The unit tests are written before and during development. They need to test each component as they are made. Integration tests however, are carried out once you have nearly finished code. In IN1910 we focus on writing automated unit tests with pytest, and then finding some good example case where we can compare the output to a known analytic solution as our integration case.
Regression testing#
A different kind of term you might come across is called “regression testing”. This isn’t really a third type of test, but is more descriptive of the goal of the testing. A “regression” in this sense means a step back, and the goal of regression tests are to make sure that code that has been implemented and works, isn’t changed and broken. In this sense, unit tests can be a type of regression test. Say you have a well-tested piece of code with plenty of unit tests. Now you want to refactor, change or optimize that code in some way. Then you can rerun all your unit tests after incorporating your changes, and thus check for regressions.
In larger software projects, regression tests are also used to fix bugs. When a bug or issue is found, the first step is often to find out how to reproduce that bug reliably. Here the developers often ask for a minimal working example, i.e., the least amount of code needed to cause the bug to happen. This minimal working example can be made into a test. This is extremely useful in the long run because this will become an automatic regression test. When the bug is fixed, the newly created test will pass. If the bug is ever reintroduced later, the regression test will immediately catch it.
Agile software development#
Agile software development is a modern (2001-) set of software development methods that is seeing frequent use in the industry. It focuses tools, methods and structures that make it easier to develop software quickly and efficiently, while maintaining quality and flexibility.
In agile software development, there is a strong focus on testing, and especially on test-driven development. Test driven development means that all development is focused around testing, rather than doing testing as an afterthought. In fact, ideally, one writes the tests first, and then you develop code until that test passes. This way, it is clear when the code is doing what it is supposed to do. In this way, the tests can be seen also as a code specification.
One of the main ideas of test-driven development can be summarized by:
Write tests first, otherwise you’ll write them never
Testing and Version Control#
As mentioned earlier, for testing to be as efficient as possible, we want to automate testing. This ideally also means that we shouldn’t need to run the tests ourselves, rather it should happen automatically every time we change the code. For a software project, the code changes when someone commits and pushes new code. Because of this, it should come as no surprise that there are many tools possible to automate the running of all tests in a git repository any time that code is changed.
Tools that do this are often known as often known as continuous integration tools, and these “watch” our repository and lets us know when something seems to break. CI tools can also do other kinds of testing, such as “building” where it sets up a clean virtual machine, installs all the dependencies of your code, installs your code, and then runs all the tests. This way, the CI watcher can also catch when your code breaks not because you introduced some bug, but because some other package is changed somehow. CI can automate such build-tests at regular intervals, perhaps several times a day.
The most popular CI tool for Github is Travis CI, but many other options exist, such as Jenkins and Bitbucket Bamboo.
Setting up CI monitoring is recommended if you ever write software you want others to start using.
Test coverage#
Finally. If testing is a crucial part of good software, how can we measure how well a software is tested? Having some tests is better than having no tests. But is having many tests a guarantee of good code? The short answer is: no, it isn’t. One metric of measuring how well software is tested is called test coverage. It is a simple measurement of how much of the code is actually run when running the tests.
There are different ways to measure “coverage”, but the simplest way is usually “line coverage”, which simply denotes the percentage of lines that are actually run when going through all the tests. If we have a line coverage of 30%, then the unit tests only use 30% of the actual code, and so 70% of the code is never actually tested.
pytest comes with many plugins, and one of them is pytest-cov which can be used to check coverage for us when we run our unit tests. To use it you first need to install the plugin
!pip install pytest-cov
If you have the plugin, you can do
pytest --cov
And you will get an output that shows how our line coverage is. It automatically reports on any file that is invoked in the tests, which means it might spew out tons of info on packages such as numpy and scipy. To avoid this we can do
pytest --cov=vector
which tells pytest to only report coverage from the package “vector”, which in this case means the vector.py file, but it could be a folder as well. Running our command, we now get the output
.........
Name Stmts Miss Cover
-------------------------------
vector.py 60 14 77%
----------------------------------------------------------------------
Ran 9 tests in 0.070s
OK
Here “Stmts” are the number of statements, i.e., code lines, in the vector.py module, “Miss” are the number of lines that are not covered, and “Cover” shows the line coverage as a percentage. In this case we have 77% coverage, not too shabby.
There are many other tools for checking line coverage, and some editors and IDE’s lets you do it straight in the editor. CI tools can also automatically check and show coverage on your repository as a HTML “badge”. See for example the requests repository.
Note that coverage is a much used and referred to because it is easy to measure and can be done automatically. However, it is far from perfect. A code with 100% test coverage is not guaranteed to be error-free, and a code with 30% coverage can be better tested than one with 70%.
Avoiding Confirmation Bias#
Confirmation bias is the tendency of trying to verify your own hypotheses, rather than trying to refute them. The same tendency can be found in software developers, that they tend to write tests that prove their code works, rather than write tests that get the code to fail.
It is important to remember the goal of testing is to find errors in the code and fix them. When writing tests, you should therefore try to avoid confirmation bias and write tests that are a bit vicious. Put simply, good tests try to break the code.
There is a famous logic puzzle that illustrates confirmation bias well, called the four-card problem. See if you can solve it.
Problem: Suppose you have a deck of cards, where each card has a letter on one side, and a number on the other. On the table in front of you, there are 4 cards, shown below. We now propose the following hypothesis: “If a card has a vowel on one side, then the other side is an even number.”. Which cards are worthwhile to flip over to test this hypothesis?
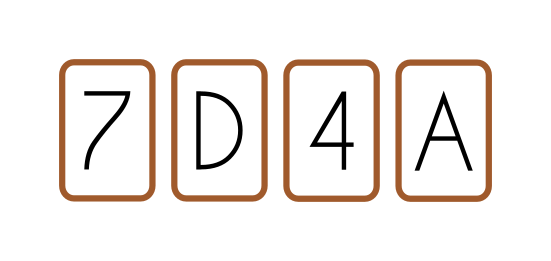
Solution: This problem was originally formulated by psychologist Peter Cathcart Wason in 1966, who proceeded to test university students with it. They found that “A and 4” was the most common answer (46%), followed by “Just A” (32%). Both of these answers are wrong. Because A is a vowel, turning this card over is useful, because if the card on the other side is odd, then we have disproved the hypothesis. Turning over the 4 however, isn’t helpful, because the state hypothesis is “one-way”, i.e., it states “if vowel, then even number”, not vice versa. However, we should flip the 7 over, as this is an odd number, and so if there is a vowel on the other side, then we have disproved the hypothesis! Thus the answer is “A and 7”.
Wason’s logic puzzle is a good illustration of confirmation bias. Most people when confronted with the riddle want to try to prove the hypothesis, when they should be trying to disprove it. The take away to software development is that good tests try to break code, not confirm that it works!
Exit codes#
In this section we will cover a topic that might seem a bit strange but will make more sense when we transition from python to C++. Imagine that you want to chain together two commands in the terminal, meaning that you for example first want to run a python program and if that completes without errors you would like to do something else. Consider the following program
# divide.py
import sys
def main(args):
if len(args) != 2:
print("You need to provide 2 arguments")
else:
print(f"The result is {float(args[0]) / float(args[1])}")
if __name__ == "__main__":
main(sys.argv[1:])
You need to provide 2 arguments
Here we ask the user to provide two numbers and the program will print the first number divided by the second, e.g
$ python divide.py 4 2
The result is 2.0
The execution of this program was successful because it ran without any errors. We can verify this by checking that the exit code is 0
$ echo $?
0
Here echo is the equivalent of print in python, but in bash, and $? just mean the exit code of the last running program.
If you try to run the program with the input 1 and 0 you will get the following
$ python divide.py 1 0
Traceback (most recent call last):
File "/Users/henriknf/divide.py", line 12, in <module>
exit(main(sys.argv[1:]))
File "/Users/henriknf/divide.py", line 8, in main
print(f"The result is {float(args[0]) / float(args[1])}")
ZeroDivisionError: float division by zero
and now the exit code is 1
echo $?
1
Why is this important? If you have a big program the consist of several programs then exit codes are a way to tell the next program if the previous program failed. In bash you can chain together programs using &&, for example
$ python divide.py 4 2 && echo 'Success!'
The result is 2.0
Success!
and we we that ‘Success!’ is printed after the python program is finished. However, if you try
$ python divide.py 1 0 && echo 'Success!'
Traceback (most recent call last):
File "/Users/henriknf/test/divide.py", line 12, in <module>
main(sys.argv[1:])
File "/Users/henriknf/test/divide.py", line 8, in main
print(f"The result is {float(args[0]) / float(args[1])}")
ZeroDivisionError: float division by zero
you will only get the error and not the message ‘Success!’. This is because bash knows that it should stop if it receives a non-zero exit code.
Now, you may want to also abort the program if you provided to few or too many arguments to the script, but currently we get the following behavior if you for example try to provide three arguments
$ python divide.py 4 2 3 && echo 'Success!'
You need to provide 2 arguments
Success!
which is not what we want. One way to handle this is to return an exit code from the program to the exit method so that your program becomes
import sys
def main(args):
if len(args) != 2:
print("You need to provide 2 arguments")
return 2
else:
print(f"The result is {float(args[0]) / float(args[1])}")
if __name__ == "__main__":
exit(main(sys.argv[1:]))
You need to provide 2 arguments
Note that the value 2 (which is chosen somewhat arbitrarily) is returned and passed to the exit method if the number of arguments are different from two. If we try to repeat the procedure above we get
$ python divide.py 4 2 3 && echo 'Success!'
You need to provide 2 arguments
which is what we want. Note that if you want to continue the program even if a failure occurs (such as ZeroDivisionError) you can just add a try-except block and just suppress the error that way.